前言 OpenLA500 的 dcache 是一个简单的 cache,实现了 《CPU 设计实战》中 有关cache 的所有需求,因此它值得研究和学习。
体系结构 cache 是内存的一部分内容拷贝,因此 CPU 访存的时候首先访问 cache,若命中就返回,若未命中就会 refill 然后返回(数据或者 write 的 OK 信息)。
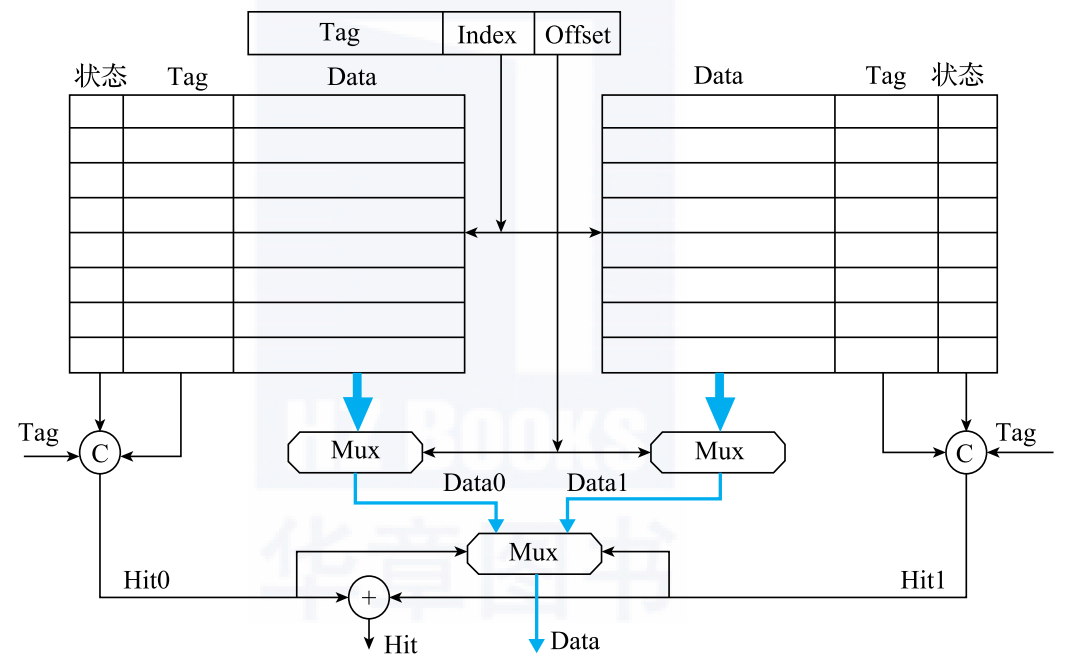
cache 的三种映射方式中,组相联是最好的,它结合了全相联和直接映射的优点。 OpenLA500 中使用了 2 路组相连,cache line 大小为 16B,2 路 cache 的 data 一共 8KB,每一路的 cache line 有 256 个。
因此,可以计算出规格为:
1 2 3 4 5 wire [31 :0 ] vaddr;wire [3 :0 ] offset = vaddr[3 :0 ];wire [7 :0 ] index = vaddr[11 :4 ];wire [19 :0 ] tag = vaddr[31 :12 ];
映射示意图如下:
首先按照 vaddr 的 index 域进行查找,找到两路 tag 和 状态位,比如脏位 D、有效位 V。接着比较 Tag 算出 Hit,再根据 Offset 选出 rdata。
cache cache 行为分析 我们依据在读、写操作访问 Cache 执行过程中所属的不同阶段,将对 Cache 模块
Look Up:Read,进行 cache 命中尝试,可能命中也可能不命中。命中返回读取数据;
Hit Write:Write,如果命中进行这个操作;
Replace:如果没命中,随机选取一个 way,将对应的index 的 cache line 标记,这就是腾出的位置,供 Refill 使用;
Refill:就返回的 16B 数据填入cache line,当然还得注意 Repalce 的 cache line 是否有脏位,如果有,得写回去。
总结下来,一共需要这几张表:
TAGV RAM:选用 RAM 256×21(深度 × 宽度),共实例化 2 块,每路 1 块。
DATA Bank RAM:选用 RAM 256×32(深度 × 宽度),共实例化 8 块,每路 4 块。
cache 模块的 io 《CPU设计实战》建议了以下接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 module cache(input wire valid,input wire op, input wire [7 :0 ] index,input wire [19 :0 ] tag, input wire [3 :0 ] offset,input wire [3 :0 ] wstrb,input wire [31 :0 ] wdata,output wire addr_ok,output wire data_ok,output wire [31 :0 ] rdata,output wire rd_req,output wire [2 :0 ] rd_type,output wire [31 :0 ] rd_addr,input wire rd_rdy,input wire ret_valid,input wire ret_last,input wire [31 :0 ] ret_data,output wire wr_req,output wire [2 :0 ] wr_type,output wire [31 :0 ] wr_addr,output wire [3 :0 ] wr_wstrb,output wire [31 :0 ] wr_data,input wire wr_rdy
cache 内部除 cache 表之外的数据通路 《CPU设计实战》建议了对 cache 的四种操作:Look Up、Hit Write、Replace 和 Refill。
当 cache 被设计成阻塞式时,这意味着 Look Up、Replace & Refill 可以复用内部的一些数据通路。它们的核心部分是 Request Buffer、Tag Compare、Data Select、Miss Buffer 和 LFSR。Hit Write 是游离于 Look Up 和 Replace & Refill 之外的单独访问,其核心部分是 Write Buffer。
Request Buffer Request Buffer 是为了将当前的请求锁存下来,因为请求数据要用多个周期。
1 2 3 4 5 6 reg request_buffer_op;reg [ 7 :0 ] request_buffer_index;reg [19 :0 ] request_buffer_tag;reg [ 3 :0 ] request_buffer_offset;reg [ 3 :0 ] request_buffer_wstrb;reg [31 :0 ] request_buffer_wdata;
Tag Compare Tag Compare 数据通路是将每一路 Cache 中读出的 Tag 和 Request Buffer 寄存下来的 tag(记为 reg_tag)进行相等比较,生成是否命中的结果。
1 2 3 4 5 6 7 8 generate for (i=0 ;i<2 ;i=i+1 ) begin :gen_way_hitassign way_hit[i]= way_tagv_douta[i][0 ] && (tag == way_tagv_douta[i][20 :1 ]);end endgenerate assign cache_hit = |way_hit;
Data Select Data Select 数据通路是对两路 Cache 中读出的 Data 信息进行选择,得到各种访问操作需要的结果。
对于 Replace,replace_way 指定哪一路就把哪一路的数据拿出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 generate for (i=0 ;i<2 ;i=i+1 ) begin :gen_way_dataassign way_data[i] = {way_bank_douta[i][3 ],2 ],1 ],0 ]};assign way_load_word[i] = way_data[i][request_buffer_offset[3 :2 ]*32 +: 32 ];end endgenerate assign load_res = {32 {way_hit[0 ]}} & way_load_word[0 ] |32 {way_hit[1 ]}} & way_load_word[1 ];assign replace_data = replace_way ? way1_data : way0_data;
Miss Buffer Miss Buffer 用于记录缺失 Cache 行准备要替换的路信息,以及已经从 AXI 总线返回了几个 32 位数据。缺失处理时需要的地址、是否是 Store 指令等信息依然维护在 Request Buffer 中。
LFSR LFSR 是线性反馈移位寄存器(Linear Feedback Shift Register),我们采用伪随机替换算法,LFSR 会作为伪随机数源。
Write Buffer Write Buffer 是在 Hit Write(Store 操作在 Look Up 时发现命中 Cache)时启动的,它会寄存 Store 要写入的 way、bank、index、bank 内字节写使能和写数据,然后使用寄存后的值写入 cache 中。
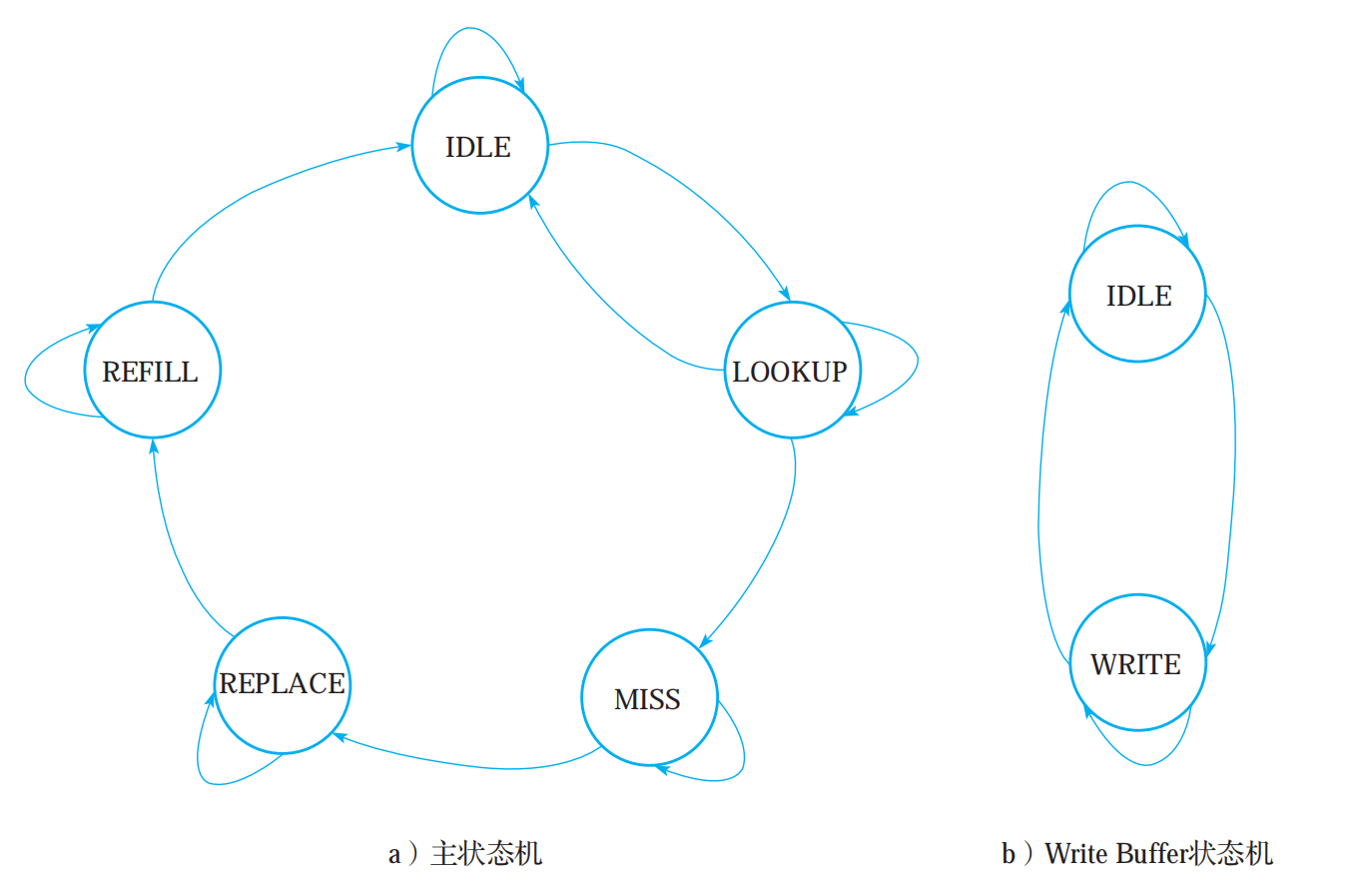
cache 状态机 《CPU设计实战》建议的是一个阻塞式的 cache,cache 缺失的时候不会接收新的请求,因此 Look Up 和 Replace & Refill 处理可以共用一个状态机,称之为主状态机。另外,Hit Write 是游离
1 2 3 4 5 6 7 8 9 10 11 localparam main_idle = 5'b00001 ;localparam main_lookup = 5'b00010 ;localparam main_miss = 5'b00100 ;localparam main_replace = 5'b01000 ;localparam main_refill = 5'b10000 ;localparam write_buffer_idle = 1'b0 ;localparam write_buffer_write = 1'b1 ;reg [4 :0 ] main_state;reg write_buffer_state;
状态机状态转移图如下:
非缓存访问的处理 LoongArch32 精简版支持两种存储访问类型,分别是一致可缓存(Coherent Cache,CC)和强序非缓存(Strongly-ordered Uncached,SUC)。
比如,绝大多数外设的状态寄存器和控制寄存器就不能采用可缓存类型的存储访问。比如,要控制某个设备,得往某一个内存进行写入操作,但是如果仅仅写到了 cache 中,这个设备将不会有任何影响;同理,如果设备往某一个地址中写了值,CPU 仅仅读取了 cache,也达不到目标效果。
因此,发往 cache 的请求必须携带一个信息,要能区分当前请求是可缓存还是不可缓存。如果是非缓存,就可以复用 Cache Miss 的数据通路,也就是给 AXI 发请求,然后直接返回。
这个复用非常重要:举个例子来说,一个非缓存的 load 指令携带着非缓存的标志进入 Cache 模块后,Cache 模块内部也会检查一下 Cache,然后并不看 Cache Tag 的比较结果而是直接将其当作 Cache Miss 进行后续处理。因为 Cache 缺失时要向总线外发送访存请求,所以非缓存自然就利用这个流程发起总线请求,然后等待数据返回,只不过此时不需要真的替换一个 Cache 行。怎么区分呢?那就要看当前的 Request Buffer 中记录的存储访问类型了。
cache 维护指令:cacop CACOP 指令主要用于 Cache 的初始化以及 Cache 一致性维护。它能对 cache 进行一些操作,比如:
Invalid 操作实质上就是把相应 Cache 行的 V 写成 0;
部分 CACOP 指令要对 Cache 进行 Hit 判断;
部分 CACOP 指令需要读出一个 Cache 行并将其写回内存。
因此 CACOP 本质上就是在 Cache 中进行一些操作,而这些操作已经被解耦且实现了。
OpenLA500 dcache 的数据通路 CPU接口信号
valid : CPU请求有效信号,表示CPU发起了一次访问请求op : 操作类型 (0=读操作, 1=写操作),缓存指令被视为读操作size[2:0] : 访问数据大小编码 (000=1B, 001=2B, 010=4B, 011=8B, 100=16B等)index[7:0] : 缓存索引,用于选择缓存行 (8位=256个缓存行)tag[19:0] : 缓存标签,用于标识缓存行offset[3:0] : 块内偏移,用于选择缓存行内的字节wstrb[3:0] : 写字节使能,每位对应一个字节的写使能wdata[31:0] : 写数据addr_ok : 地址握手信号,表示缓存可以接受新请求data_ok : 数据握手信号,表示数据已准备好rdata[31:0] : 读取的数据
特殊操作信号
uncache_en : 非缓存访问使能,绕过缓存直接访问内存dcacop_op_en : 数据缓存操作指令使能cacop_op_mode[1:0] : 缓存操作模式
00: 存储标签 (Store Tag)
01: 索引无效 (Index Invalidate)
10: 命中无效 (Hit Invalidate)
11: 索引无效 (Index Invalidate)
preld_hint[4:0] : 预取提示信息preld_en : 预取使能信号tlb_excp_cancel_req : TLB异常取消请求sc_cancel_req : 条件存储取消请求dcache_empty : 缓存空闲状态指示
AXI总线接口信号 读通道
rd_req : 读请求信号rd_type[2:0] : 读传输类型 (与size编码相同)rd_addr[31:0] : 读地址rd_rdy : 读请求就绪信号ret_valid : 返回数据有效信号ret_last : 最后一个返回数据信号ret_data[31:0] : 返回的数据
写通道
wr_req : 写请求信号wr_type[2:0] : 写传输类型wr_addr[31:0] : 写地址wr_wstrb[3:0] : 写字节选通wr_data[127:0] : 写数据 (可写整个缓存行128位)wr_rdy : 写请求就绪信号
性能计数器接口
状态机相关
main_state[4:0] : 主状态机状态
main_idle (00001): 空闲状态
main_lookup (00010): 查找状态
main_miss (00100): 未命中状态
main_replace (01000): 替换状态
main_refill (10000): 重填状态
write_buffer_state : 写缓冲状态机
请求缓冲器 保存当前处理的请求信息:
request_buffer_op : 缓存的操作类型request_buffer_size[2:0] : 缓存的访问大小request_buffer_index[7:0] : 缓存的索引request_buffer_tag[19:0] : 缓存的标签request_buffer_offset[3:0] : 缓存的偏移request_buffer_wstrb[3:0] : 缓存的写使能request_buffer_wdata[31:0] : 缓存的写数据request_buffer_uncache_en : 缓存的非缓存访问标志request_buffer_dcacop : 缓存的cacop操作标志request_buffer_cacop_op_mode[1:0] : 缓存的cacop模式
未命中处理
miss_buffer_replace_way[1:0] : 未命中时要替换的路miss_buffer_ret_num[1:0] : 返回数据的计数器ret_num_add_one[1:0] : 返回计数器加1
写缓冲器
write_buffer_index[7:0] : 写缓冲索引write_buffer_wstrb[3:0] : 写缓冲字节使能write_buffer_wdata[31:0] : 写缓冲数据write_buffer_way[1:0] : 写缓冲路选择write_buffer_offset[3:0] : 写缓冲偏移
存储器接口信号 数据存储器 (每路4个bank)
way_bank_addra[1:0][3:0][7:0] : 数据bank地址way_bank_dina[1:0][3:0][31:0] : 数据bank输入数据way_bank_douta[1:0][3:0][31:0] : 数据bank输出数据way_bank_ena[1:0][3:0] : 数据bank使能way_bank_wea[1:0][3:0][3:0] : 数据bank写使能
Tag&V 存储器
way_tagv_addra[1:0][7:0] : 标签地址way_tagv_dina[1:0][20:0] : 标签输入 [20:1]=标签, [0]=有效位way_tagv_douta[1:0][20:0] : 标签输出way_tagv_ena[1:0] : 标签使能way_tagv_wea[1:0] : 标签写使能
缓存逻辑信号
way_d_reg[255:0][1:0] : 脏位寄存器数组way_d[1:0] : 当前访问的脏位状态way_hit[1:0] : 路命中信号cache_hit : 缓存命中信号way_load_word[1:0][31:0] : 每路加载的字way_data[1:0][127:0] : 每路的完整缓存行数据load_res[31:0] : 最终的加载结果
替换策略信号
replace_data[127:0] : 要替换的数据replace_d : 替换行的脏位replace_v : 替换行的有效位replace_tag[19:0] : 替换行的标签random_val[1:0] : 随机值 (用于随机替换)chosen_way[3:0] : 选择的路 (解码后)replace_way[1:0] : 最终替换的路invalid_way[1:0] : 无效路has_invalid_way : 是否有无效路rand_repl_way[1:0] : 随机替换路
控制信号
main_idle2lookup : 从空闲到查找状态转换条件main_lookup2lookup : 查找状态保持条件main_state_is_xxx : 各状态判断信号write_state_is_xxx : 写状态判断信号cancel_req : 取消请求信号req_or_inst_valid : 请求或指令有效信号
非缓存访问信号
request_uncache_en : 请求的非缓存访问标志uncache_wr : 非缓存写操作uncache_wr_buffer : 缓存的非缓存写标志uncache_wr_type[2:0] : 非缓存写类型
缓存操作指令信号
cacop_op_mode0/1/2 : 各种cacop模式判断cacop_op_mode2_hit_wr : mode2命中写信号cacop_chose_way[3:0] : cacop选择的路
预取信号
preld_st_en : 预取存储使能preld_ld_en : 预取加载使能preld_ld_st_en : 预取加载存储使能
其他控制信号
way_wr_en[1:0] : 路写使能refill_data[31:0] : 重填数据write_in[31:0] : 写入数据 (考虑字节使能)rd_req_buffer : 读请求缓冲lookup_way_hit_buffer[1:0] : 查找命中缓冲
OpenLA500 dcache 的控制逻辑 main 状态机 这里需要围绕状态机的几种状态,来分析 cache 模块的 io 情况。
reset reset 信号很容易被忽视,事实上,在大部分情况下,只要模块中设计存在寄存器,比如常见的状态机、时序电路等,一般都需要进行 reset。但也有例外,比如 CSR 的某些未定义的位(按理说不能够简单的 reset 成 0,但是这样做也无妨,毕竟 CSR 中某些未定义的位也不会用到)。
main 状态机中 reset 了一些触发器,比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 main_state <= main_idle;1'b0 ;1'b0 ;3'b0 ;8'b0 ;20'b0 ;4'b0 ;4'b0 ;32'b0 ;1'b0 ;2'b0 ;1'b0 ;2'b0 ;1'b0 ;
main_idle 接下来进入了 main_idle 状态,这个时候就可能会接收到来自 CPU (IFU、IDU、EXU)的请求了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 main_idle: begin if (req_or_inst_valid && main_idle2lookup) begin end end
注意到,这里有一个条件才能进行下一步的状态转移:req_or_inst_valid && main_idle2lookup。
事实上:
1 2 assign req_or_inst_valid = valid || dcacop_op_en || preld_en;assign main_idle2lookup = !(write_state_is_full && ((write_buffer_offset[3 :2 ] == offset[3 :2 ]) || dcacop_op_en));
对于 req_or_inst_valid,我的理解是,请求有效有三个源头,分别是:
常规请求:比如 inst、data 的读写;
cacop 指令;
数据预加载,可能用于性能提升?
对于 main_idle2lookup,这个信号用来阻塞 idle 进入 lookup 的。什么时候不能进入 lookup 呢?请求冲突的时候。因此后面的逻辑给出了什么情况下会冲突。write_state_is_full 的生成逻辑为 assign write_state_is_full = (write_buffer_state == write_buffer_write);,此时是写命中的处理过程。也就是说,当写事务正在处理并且写的 cache line 的某个字和当前请求的字冲突,或者当前的写事务是由于 cacop 引起的,那么就要阻塞。这种情况下只能等写事务完成后才能处理新的请求。
main_lookup: 再来看下一个状态 main_lookup:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 main_lookup: begin if (req_or_inst_valid && main_lookup2lookup) begin end else if (cancel_req) begin end else if (!cache_hit) begin if (uncache_wr || ((replace_d && replace_v) && (!request_uncache_en || cacop_op_mode2_hit_wr) && !cacop_op_mode0))else begin end end else begin end end
这个状态是在进行 cache 命中测试,根据命中有请求、命中无请求、未命中等情况有三个下一级状态:
main_lookup:命中且有新请求且无冲突,就继续处理请求;
main_idle:请求取消、命中有新请求,重新回到空闲状态;
main_miss:如果有非缓存写或者被替换的 cache line 脏位有效,那么直接写穿(write through);
main_replace:进入替换 cache line 的状态。
lookup2lookup lookup2lookup 逻辑为:
1 2 3 4 assign main_lookup2lookup = !(write_state_is_full && ((write_buffer_offset[3 :2 ] == offset[3 :2 ]) || dcacop_op_en)) &&3 :2 ] == offset[3 :2 ]) || dcacop_op_en)) &&
这个逻辑有点复杂,如果当前有写事务,并且写事务和当前的请求冲突或者这个写请求是由于 cacop 引起,并且当前正在处理的请求是写,新请求是读且有冲突。如果前面的情况是否定的,那么此时命中了,就说明可以继续处理请求了。
如果当前的请求被取消了,那么相当于没有新的请求,回到 idle。
看看命中信号的 cache_hit 是怎么生成的。
cache_hit 1 2 3 4 5 6 7 8 generate for (i=0 ;i<2 ;i=i+1 ) begin :gen_way_hitassign way_hit[i] = way_tagv_douta[i][0 ] && (tag == way_tagv_douta[i][20 :1 ]); end endgenerate assign cache_hit = |way_hit && !(uncache_en || cacop_op_mode0 || cacop_op_mode1 || cacop_op_mode2);
对于 way_tagv_douta 信号:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 assign addr_ok = (main_state_is_idle && main_idle2lookup) || (main_state_is_lookup && main_lookup2lookup);generate for (i=0 ;i<2 ;i=i+1 ) begin :gen_tagv_wayassign way_tagv_addra[i] = {8 {addr_ok }} & index|8 {!addr_ok}} & request_buffer_index ;assign way_tagv_ena[i] = (!request_buffer_uncache_en) || main_state_is_idle || main_state_is_lookup;assign way_tagv_wea[i] = miss_buffer_replace_way[i] && main_state_is_refill &&assign way_tagv_dina[i] = (cacop_op_mode0 || cacop_op_mode1 || cacop_op_mode2_hit_wr_buffer) ? 21'b0 : {request_buffer_tag, 1'b1 };end endgenerate
首先,addr_ok 这个信号是通知上游 cache 已经接收到了 addr。addr_ok 有两个路径:
当前状态空闲且当前请求无冲突;
当前状态为 lookup 且可以接受新请求。
对于 tagv 表,发射的地址为 index,2 路都会接受到这个地址。如果 addr_ok,那么说明最新的 index 有效,直接处理最新请求;否则处理缓存起来的 index。
另外,对于非缓存访存,不能命中。
当没有命中的时候,有两种情况:
就是当前请求是非缓存请求且是写请求;
被替换的 cache line 的脏位是有效的。
这两种情况都应该直接当做 miss 处理。否则,就进入 replace 状态,因为没有命中就应该替换掉 cache line。
main_miss 1 2 3 4 5 6 7 8 main_miss: begin if (wr_rdy) begin 1'b1 ;end end
main_miss 状态要将 cache line 写会到 axi 中的 16B 的 buffer 中,axi 拿到这个 cache line 的数据口将通过 axi 接口和 sram 进行交互,将 buffer 中的 16B 数据多次写回到 sram 中。cache 写回到 axi buffer 之前要确定 axi buffer 空闲,这样才能发送写请求。
当 wr_req 有效时,以下信号都应该就绪:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 output [ 2 :0 ] wr_type ,output [31 :0 ] wr_addr ,output [ 3 :0 ] wr_wstrb ,output [127 :0 ] wr_data ,.in ({1'b0 ,random_val[0 ]}),.out (chosen_way));#(2) sel_one_invalid (.in(~{way_tagv_douta[1][0],way_tagv_douta[0][0]}),.out(invalid_way),.nozero(has_invalid_way)) ;assign rand_repl_way = has_invalid_way ? invalid_way : chosen_way[1 :0 ]; .in ({1'b0 ,request_buffer_offset[0 ]}),.out (cacop_chose_way));assign replace_way = {2 {cacop_op_mode0 || cacop_op_mode1}} & cacop_chose_way[1 :0 ] |2 {cacop_op_mode2}} & way_hit |2 {!request_buffer_dcacop}} & rand_repl_way;assign way_d = way_d_reg[request_buffer_index] |2 {(write_buffer_index == request_buffer_index) && write_state_is_full}} & write_buffer_way;assign replace_d = |(replace_way & way_d);assign replace_v = |(replace_way & {way_tagv_douta[1 ][0 ],way_tagv_douta[0 ][0 ]});assign replace_tag = {20 {miss_buffer_replace_way[0 ]}} & way_tagv_douta[0 ][20 :1 ] |20 {miss_buffer_replace_way[1 ]}} & way_tagv_douta[1 ][20 :1 ] ;assign replace_data = {128 {miss_buffer_replace_way[0 ]}} & way_data[0 ] |128 {miss_buffer_replace_way[1 ]}} & way_data[1 ] ;assign wr_type = uncache_wr_buffer ? uncache_wr_type : 3'b100 ; assign wr_addr = uncache_wr_buffer ? {request_buffer_tag, request_buffer_index, request_buffer_offset} :4'b0 };assign wr_data = uncache_wr_buffer ? {96'b0 , request_buffer_wdata} : replace_data;assign wr_wstrb = uncache_wr_buffer ? request_buffer_wstrb : 4'hf ;
main_replace 1 2 3 4 5 6 7 main_replace: begin if (rd_rdy) begin 2'b0 ; end 1'b0 ;end
replace 要从 axi 中读取 data,将 data 送到 buffer 中,然后一次性 refill 到 cache line 中。
因此,只需要在 replace 中确定 rd_rdy 后,发起 rd_req。由于要读取 4 个字,因此需要计数。当读够 4 个字后就完成了 repalce。
1 2 3 4 5 6 7 assign rd_req = main_state_is_replace && !(uncache_wr_buffer || cacop_op_mode0 || cacop_op_mode1 || cacop_op_mode2);assign rd_type = request_buffer_uncache_en ? request_buffer_size : 3'b100 ;assign rd_addr = request_buffer_uncache_en ? {request_buffer_tag, request_buffer_index, request_buffer_offset} : {request_buffer_tag, request_buffer_index, 4'b0 };
当 main_state 为 replace 的时候,就可以给 axi 发起读请求了。同时,根据是否是非缓存访问来确定具体的请求参数。
main_refill 1 2 3 4 5 6 7 8 9 10 11 12 13 main_refill: begin if ((ret_valid && ret_last) || !rd_req_buffer) begin end else begin if (ret_valid) begin end end end
这就就是充填 cache 的状态了。如果 axi 传来了 ret_last 为真,说明已经传送完成,否则继续累加。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 assign data_ok = ((main_state_is_lookup && (cache_hit || request_buffer_op || cancel_req)) ||3 :2 ]) || request_buffer_uncache_en))))) &&assign write_in = {(request_buffer_wstrb[3 ] ? request_buffer_wdata[31 :24 ] : ret_data[31 :24 ]),2 ] ? request_buffer_wdata[23 :16 ] : ret_data[23 :16 ]),1 ] ? request_buffer_wdata[15 : 8 ] : ret_data[15 : 8 ]),0 ] ? request_buffer_wdata[ 7 : 0 ] : ret_data[ 7 : 0 ])};assign refill_data = (request_buffer_op && (request_buffer_offset[3 :2 ] == miss_buffer_ret_num)) ? write_in : ret_data;assign way_wr_en = miss_buffer_replace_way & {2 {ret_valid}};
tagv 的更新 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 generate for (i=0 ;i<2 ;i=i+1 ) begin :gen_tagv_wayassign way_tagv_addra[i] = {8 {addr_ok }} & index|8 {!addr_ok}} & request_buffer_index ;assign way_tagv_ena[i] = (!request_buffer_uncache_en) || main_state_is_idle || main_state_is_lookup;assign way_tagv_wea[i] = miss_buffer_replace_way[i] && main_state_is_refill &&assign way_tagv_dina[i] = (cacop_op_mode0 || cacop_op_mode1 || cacop_op_mode2_hit_wr_buffer) ? 21'b0 : {request_buffer_tag, 1'b1 };end endgenerate
dirty flag 的更新 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 always @(posedge clk) begin if (main_state_is_refill &&begin 0 ] <= miss_buffer_replace_way[0 ] ? request_buffer_op : way_d_reg[request_buffer_index][0 ];1 ] <= miss_buffer_replace_way[1 ] ? request_buffer_op : way_d_reg[request_buffer_index][1 ];end else if (write_state_is_full) begin end end
data_back 的更新 每一个 data_back 有 4B*256,每 way 有 4 个 data_back。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 generate for (i=0 ;i<2 ;i=i+1 ) begin :gen_data_wayfor (j=0 ;j<4 ;j=j+1 ) begin :gen_data_bankassign wr_match_way_bank[i][j] = write_state_is_full && (write_buffer_way[i] && (write_buffer_offset[3 :2 ] == j[1 :0 ]));assign way_bank_addra[i][j] = wr_match_way_bank[i][j] ? write_buffer_index : ({8 {addr_ok}} & index |8 {!addr_ok}} & request_buffer_index);assign way_bank_wea[i][j] = {4 {wr_match_way_bank[i][j]}} & write_buffer_wstrb |4 {main_state_is_refill && (way_wr_en[i] && (miss_buffer_ret_num == j[1 :0 ]))}} & 4'hf ;assign way_bank_dina[i][j] = {32 {write_state_is_full}} & write_buffer_wdata |32 {main_state_is_refill}} & refill_data ;assign way_bank_ena[i][j] = (!(request_buffer_uncache_en || cacop_op_mode0)) || main_state_is_idle || main_state_is_lookup;end end endgenerate
以上就是 OpenLA500的 dcache 分析情况了。以 main 状态机为核心,cache 的 io 依赖这些状态进行请求相应。
至于 icache,其实 dcache 是 icache 功能的一个超集,可以直接实例化成 icache。